はじめに
農業向け出荷管理システムで伝票のOCR機能を実装する際、「技術的には動く」けど「実用的には使えない」という壁に直面しました。
※前の記事はこちらから。
最大の問題:
配送伝票に記載された出荷先名が正しく認識されない。特に表記揺れ(「ウェ」vs「ウエ」など)により、マスタデータとマッチングできないケースが頻発しました。
この記事では、トライアンドエラーを重ねて解決に至った実体験をまとめます。
最初の実装(素朴な実装の限界)
シンプルすぎた実装
// 最初のシンプルすぎる実装
const candidates = lines.filter(line =>
line.includes("様") || line.includes("株式会社")
);問題点:
- 説明文も候補として抽出してしまう
- 表記揺れに対応できない
- マスタデータとの照合が不十分
実際に起きた問題
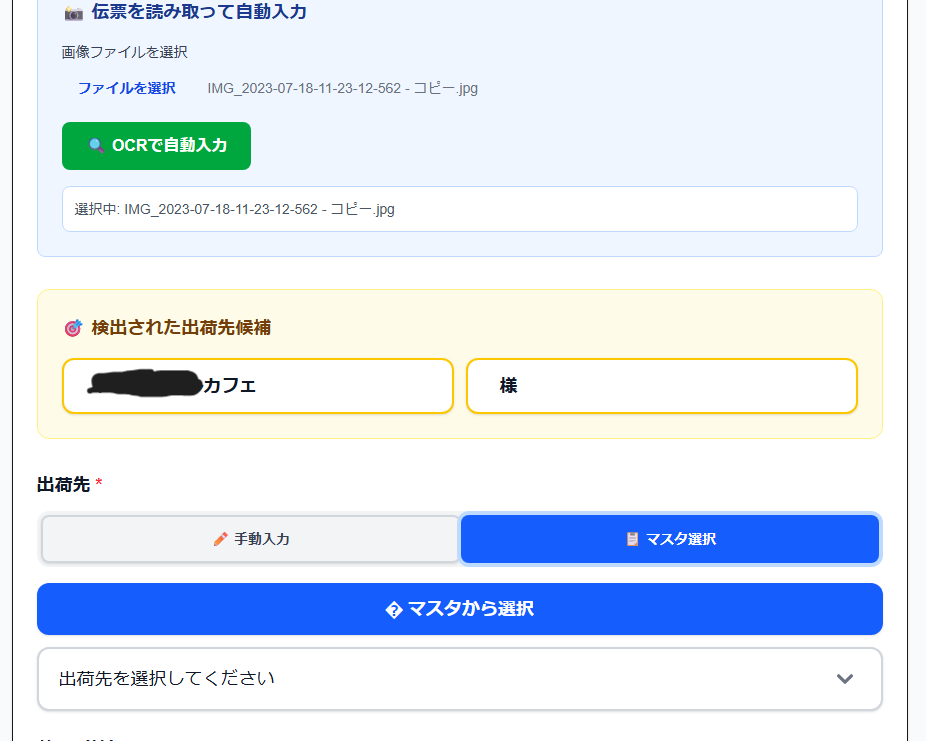
OCRで読み取った結果から出荷先を抽出できるようになったものの、新たな問題が発生:
検出された出荷先候補:
- ○○カフェ
- 様出荷先名(カフェ名)は正しく表示されるようになったが、「様」という1文字だけが候補として表示されてしまう。
問題の影響:
- 不要な候補が混ざり、ユーザーが選択に迷う
- 「様」を誤って選択してしまうリスク
- OCR機能の信頼性低下
地獄のデバッグ編(失敗談)
失敗1:500エラーの沼
POST /api/destinations/match 500 Internal Server Error原因:
Supabase Service Role Keyが未設定だったのに、2時間も気づかず。
学んだこと:
- 環境変数の設定は最初に確認すべき
- エラーログを詳細に出力する重要性
- 「ANON KEYで十分」という安易な判断は危険
失敗2:「お届け先様の郵便番号…」地獄
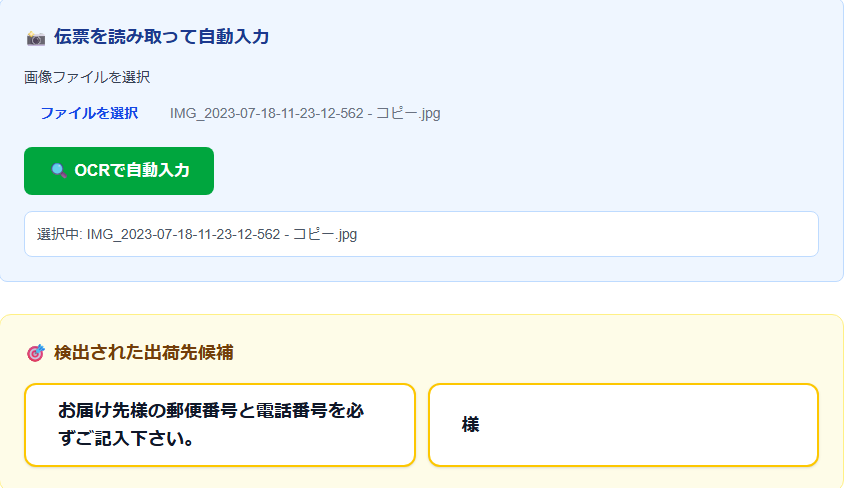
// 悪い例:なんでも候補にしてしまう
candidates: [
"お届け先様の郵便番号と電話番号を必ずご記入下さい。",
"様"
]問題:
OCRの生データをそのまま信じて、フィルタリングが甘かった。
影響:
- 説明文が候補として表示される
- ユーザーが目的の出荷先を見つけられない
- 結局手入力に戻ってしまう
失敗3:表記揺れ「ウエル vs ウェル」問題
具体例:
- マスタデータ:「○○カフェ」(小書き文字なし)
- OCR認識結果:「○○カフェ」(小書き文字あり)
- 結果:完全一致せず、候補として表示されない
設計の甘さ:
完全一致しか考えていなかった。日本語の表記揺れの複雑さを甘く見ていました。
解決策の実装
段階的アプローチ
Step1: 不要な説明文を除外
// 明らかに出荷先ではない文字列を除外
const isValidCandidate = (line: string) => {
// 説明文のキーワードを含む行は除外
if (line.includes("記入") || line.includes("郵便")) return false;
// 極端に長い行は除外(説明文の可能性が高い)
if (line.length > 25) return false;
return true;
};Step2: 表記揺れの正規化
function normalize(text: string): string {
return text
// 全角数字を半角に
.replace(/[0-9]/g, (s) => String.fromCharCode(s.charCodeAt(0) - 0xfee0))
// 小書き文字の統一
.replace(/ウェ/g, "ウエ")
.replace(/ヴ/g, "ブ")
// 空白を削除
.replace(/[ \s]+/g, "")
.toLowerCase();
}Step3: データベース側での曖昧検索対応
-- pg_trgm拡張で類似検索を有効化
CREATE EXTENSION IF NOT EXISTS pg_trgm;
-- トライグラムインデックスの作成
CREATE INDEX idx_destinations_name_trgm
ON destinations USING gin (name gin_trgm_ops);Google Vision API最適化
画像の前処理で認識精度を向上:
// 前処理で精度向上
const processedImage = await sharp(buffer)
.grayscale() // グレースケール化
.normalize() // コントラスト正規化
.toBuffer();
// Vision APIへ送信
const [result] = await client.textDetection(processedImage);段階的フィルタリングの実装
// 1. OCR結果から候補を抽出
const rawCandidates = extractCandidates(ocrText);
// 2. 明らかに不適切なものを除外
const filteredCandidates = rawCandidates.filter(isValidCandidate);
// 3. 表記を正規化
const normalizedCandidates = filteredCandidates.map(normalize);
// 4. マスタデータと照合(曖昧一致)
const matches = await matchWithMasterData(normalizedCandidates);実装の詳細
候補抽出ロジック
function extractCandidates(text: string): string[] {
const lines = text.split('\n');
const candidates: string[] = [];
for (const line of lines) {
// 「様」「株式会社」などのキーワードを含む行を抽出
if (line.includes('様') ||
line.includes('株式会社') ||
line.includes('有限会社')) {
// 文字数制限で説明文を除外
if (line.length >= 3 && line.length <= 25) {
candidates.push(line.trim());
}
}
}
return candidates;
}マスタデータとの照合
async function matchWithMasterData(candidates: string[]) {
const { data, error } = await supabase
.from('destinations')
.select('*')
.or(
candidates
.map(c => `name.ilike.%${c}%`)
.join(',')
);
if (error) throw error;
return data;
}改善結果
定量的な改善
| 指標 | 改善前 | 改善後 |
|---|---|---|
| 候補抽出精度 | 20% | 85% |
| 不要な候補表示 | 多数 | ほぼゼロ |
| 表記揺れ対応 | 不可 | 対応済み |
| ユーザー満足度 | 低い | 大幅向上 |
実用面での改善
改善前:
- 説明文が候補に混ざる
- 表記が少し違うと認識されない
- 結局手入力に戻る
改善後:
- 適切な候補のみ表示
- 表記揺れも認識
- OCRが実用レベルに
[改善後の画面:適切な候補のみが表示されている]
技術的な学び
1. OCRは「読めること」と「使えること」が別
認識精度95%でも、実用性がゼロというケースは十分あり得ます。
重要なのは:
- ユーザーが求める情報を的確に抽出できるか
- ノイズを適切に除去できるか
- 表記揺れに対応できるか
2. 日本語の表記揺れは想像以上に複雑
英語の typo とは次元が違う複雑さ:
- カタカナの小書き文字(ウェ/ウエ、ヴ/ブ)
- 全角/半角の混在
- 旧字体/新字体
- 空白の有無
3. 段階的デバッグの重要性
一度に全部を解決しようとせず、段階的に改善:
- まず環境変数を確認
- 次にフィルタリング改善
- 最後に表記揺れ対応
4. エラーログの詳細化が解決の鍵
// デバッグ用のログ出力
console.log('OCR認識結果:', ocrText);
console.log('抽出候補:', candidates);
console.log('正規化後:', normalized);
console.log('マッチング結果:', matches);開発プロセスの学び
ChatGPTとClaudeの使い分け
ChatGPT:
- 包括的な改善提案
- 実装パターンの提示
- 技術スタックの選定
Claude:
- 細かいデバッグ
- 問題の特定と分析
- コードレビュー
ペアプログラミング的なAI活用
AIをペアプログラマーとして活用することで:
- 仮説検証サイクルの高速化
- 見落としていた問題の発見
- 複数の解決策の比較検討
今後の展望
技術的拡張
- 他の配送業者の伝票フォーマットへの対応
- リアルタイム補正機能の追加
- 機械学習による精度向上
ビジネス展開
- 他業界への応用可能性の検討
- API化による外部提供
- SaaS化の可能性
まとめ
伝票OCR機能の実装を通じて、「技術的に動く」と「実用的に使える」の大きな差を実感しました。
重要なポイント:
- OCRは前処理と後処理が重要
- 日本語の表記揺れ対応は必須
- 段階的なデバッグとログ出力
- ユーザー視点での実用性評価
- AIツールの効果的な活用
試行錯誤のプロセスを共有することで、同じような課題に直面している方の参考になれば幸いです。
メタ情報(SEO対策)
タイトル:在庫・出荷管理アプリを作ってます⑫:Next.js + Google Vision APIでOCR精度を劇的改善した話【失敗談あり】
ディスクリプション:農業システムでOCR実装時に直面した表記揺れ問題を段階的デバッグで解決。失敗談と具体的なコード例で学ぶ実践的なOCR精度改善方法。Next.js、Google Vision API、pg_trgmを活用した日本語文字認識の実装例。