流通管理システムの開発も⑥段階目。今回は生産者が出荷完了後に伝票をOCRで自動登録する機能に取り組んだ。
「写真を撮るだけで伝票の内容が自動入力されたら便利だよね!」という発想で始めたのだが、そんな簡単にできるわけもなく、出来は置いといて実装だけはなんとなくできた。
目次
現在の画面イメージ

出荷先、数量、伝票番号を手入力するフォームに、OCRで自動入力する機能を追加したいと考えた。
第一候補:Tesseract OCRで挑戦
最初は無料で使えるTesseract OCRを試してみた。オープンソースで実績もあるし、コスト面でも魅力的だった。
しかし現実は厳しかった
処理速度の問題
- ブラウザ上で画像を渡すだけで処理に1分以上かかることもあり
- 実際のスマホ利用では5分近く固まったように見えるケースも
- 生産者の方が現場で使うことを考えると、この待機時間は致命的
日本語認識の問題
- 日本語対応が弱く、フォントによっては文字がぐちゃぐちゃになってしまう
- 伝票の文字は手書きもあるため、さらに精度が落ちる。
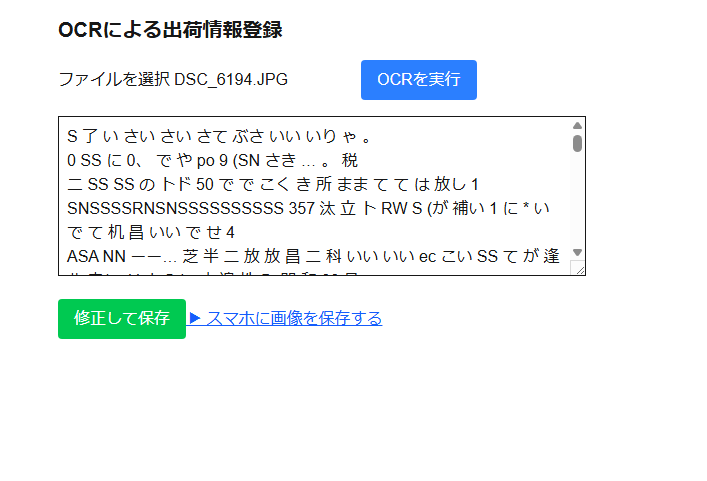
結論:実用無理
軽量さやライブラリの自由度では魅力があったが、リアルタイム性の求められる業務用途には向かなかった。
第二候補:Google Cloud Vision APIに乗り換え
Tesseractに限界を感じたため、Google Cloud Vision APIを導入することにした。
改善された点
処理速度の劇的改善
- 画像送信から数秒以内で結果が返る
- スマホでの利用でもストレスなく使える
日本語精度の向上
- 日本語の精度もTesseractよりはかなりマシ
- 伝票の印刷文字はそれなりに読み取れる
開発効率の向上
- JSONで結果が返ってくるので後処理もしやすい
- APIの仕様がしっかりしているので実装が楽
でも、まだ課題は山積み
精度の問題は残る
Vision APIはTesseractよりはだいぶ早い。けど精度がいいかと言われればそうでもない。
「様」とか「株式会社」とかで抽出したらある程度は候補として出てきたけど、完璧ではない。手書き文字や、印刷が薄い部分はやはり厳しい。
マスタ連携の課題
マスタ登録したものを候補としても出そうと思ったが、これもうまくいかず保留中。
OCRで抽出した文字列とマスタデータをどうマッチングするかは、想像以上に複雑な問題だった。
今後の課題
Google Cloud Vision APIの無料枠
- 3か月間は300ドル分のお試しがある・・・が、正直判断を誤った。実は登録したのは6月頭で結局何も試せずに、60日が過ぎてしまった。農作業との並行作業はなかなか難しい。
次のステップ
- マスタデータとの照合ロジック改善
- OCR結果の候補表示UI改善
- 手動修正しやすいフォーム設計
まとめ
OCR機能の実装は想像以上に奥が深い。技術的には実現可能だが、業務に使えるレベルまで持っていくには、単純な文字認識以上の工夫が必要だと実感した。
完璧を目指すよりも、「手入力よりは楽になる」レベルでまずリリースして、実際の使用感を見ながら改善していく方針でいこうと思う。